
DREAM: Efficient Dataset Distillation by Representative learning - Paper Blog Post
Published:
DREAM: Efficient Dataset Distillation by Representative learning
Introduction
What is Dataset distillation?
Training a network on ImageNet-1k dataset is a very heavy task, requiring multiple epochs of forward and backward pass with 1.28million different image-label pairs. Not only does the training take much time, large dataset cannot be moved to On-Devices because of the memory size. To resolve this problem, Dataset Distillation aims to compress large training dataset into lightweight dataset while maintaining its capability to train models in image classification task. With such replacement training time and energy consumption can be reduced while training can be done on On-Devices with small memory space. To accomplish this, the field of Dataset Distillation synthesizes dataset through backpropagation with variety of objectives in hand.
For clarification, ‘synthetic dataset’ is the targeted lightweight dataset that is synthesized through backpropagation during dataset distillation procedure. ‘Real training dataset’ is the actual heavy dataset that requires to be compressed. For example, given that the original CIFAR10 dataset have 5000 images per class, IPC in short, the aim is to reduce its size to 1IPC, 10IPC or 50IPC. Moreover, synthetic images are intialized as Gaussian noise images or subset of real training images.
Various Objective settings for Dataset Distillation
1. Main Objective - Dataset Distillation (2018)
First paper of Dataset Distillation[7] dates back to 2018 with a formal objective. Field of Dataset Distillation aims to make a synthetic dataset that trains network to well classify real images. To match this definition, the objective for training the synthetic image was set to ‘minimizing classification loss of real training dataset when it is forwarded on network that is trained on synthetic dataset for multiple iterations’. In this objective setting, updating synthetic dataset with backpropagation is done by computing the gradient of gradient, a Hessian, which is a very unstable optimization problem. Also, the number of iterations synthetic dataset has been used for training determines the complexity of hessian calculation. In order to update the synthetic image, the whole training steps needs to be unrolled and be used for backpropagation. This framework is called ‘BackPropagation Through Time (BPTT)’ and is why the synthetic image generation takes a very long time.
2. Surrogate Objective - Dataset Condensation with Gradient Matching (2021)
Dataset Distillation was forgotten for few years until this new surrogate objective was discovered. Gradient Matching method[3] is based on matching the gradient of synthetic dataset and real training dataset throughout the parametric trajectory when model is being trained. Objective is to minimize the MSE loss or cosine similarity loss of the two gradients, gradient of real training image and gradient of synthetic image. Then, synthetic image is updated through backpropagation calculated from that gradient matching loss. This way the synthetic image will mimic the parametric trajectory of real training image resulting in a similar paramteric space when model is trained on synthetic image, and hence a similar performance to when model is being trained on real training dataset.
Gradient matching is conducted with outer training loop and inner training loop. Outer training loop refers to update procedure being conducted on multiple randomly intialized models. This is for generalization to the random intialization of the model when synthetic image is actually utilized for training. Inner training loop trains the model on whole batch of synthetic dataset iteratively creating parameteric instances where the gradient matching is conducted. In other words, creating a parametric trajectory. Within each parametric instance, gradient matching is conducted while iterating through each class of the dataset. For example, given task of synthesizing 10IPC dataset, 10 synthetic images assigned to ‘horse’ class are gradient matched with whole real images of ‘horse’ class, and so on for each class. This way synthetic image is updated so that it will mimic the real dataset’s gradient throughout the trajectory when used for training, eventually resulting in a similar parametric convergence and a similar performance.
The paper to be reviewed in this blog post, DREAM, is not entirely based on this method, in fact a more developed gradient matching method called ‘IDC[2]’. There are two distinguishing features between naive Gradient Matching method and IDC method. Firstly, the inner training loop generates trajectory based on real training dataset mini-batches. This way the dependency between the parameteric instance and gradient computation of sythetic image can be mitigated. Also, for naive gradient matching method, the training with small synthetic dataset converges at early training and result in the gradient norm to decrease quickly leaving no gradient to be matched at later stages. On contrary, creating trajectory with real training image creates more parametric instances that are suitable for gradient matching since it converges much slower.
Nextly, IDC condenses downsampled image and resize through bilinear interpolation when used for training. To elaborate, IDC stores synthetic image as downsampled form while, when being used for gradient matching, it is restored to its original size. This means that, in 2 factor downsampling setting, the size of dataset can be diminished by 4-fold. In previous method, 1IPC worth of synthetic dataset would take up 30,720 (=32x32x3x1x10) pixel space, whereas IDC method would fit 4IPC(downsampled) in the same 30,720 (=16x16x3x4x10) pixel space. These 4IPC is counted as 1IPC by merging them in sqaure into 32x32 image and each partition is cropped then upsampled to obtain a image that can be used for training. Of course, synthetic image upsampled to original size carries less useful information compared to synthetic image updated by previous method. However, due to the natural property of ‘image’ high frequency component does not carry crucial information. Therefore, we can expect similar effect for two images in training a network. Below is the algorithm for IDC.

The distillation processes above incorporates two optimizer, one for updating the model parameter and one for updating the synthetic image.
Other than these methods there are Matching Training Trajectory method[8], distribution matching method[5], knowledge distillation method[9] and so on.
Summary
Problem Setting
Dataset distillation aims to synthesize dataset that represent the whole distribution of real dataset. While original DC method uses random sampled mini-batches of real dataset for gradinet matching, DREAM takles the lack of training efficiency in forming the mini-batch with randomly sampled images.
Previous methods use randomly sampled real image mini-batch for matching gradient with synthetic image for update at each iteration. With random sampling, each mini-batch sampled is not gaurenteed to cover the whole real dataset distribution evenly, nor consistently at every iteration. This induces each update to the synthetic image to be unstable, requiring excessive iteration for convergence. Moreover, randomly sampled mini-batches may be concentrated near certain part of decision boundary leading to larger gradient norm that serves as a noise to updating the synthetic images. In addition, previous methods intialize synthetic image with randomly sampled real image. Random intialization of synthetic image also does not provide the optimal prior condition for distillation, since it does not reflect the full distribution of the dataset.
Method
To address this problem, DREAM utilizes the well-known k-means clustering method for forming the mini-batch. This induces stable, and hence fastened optimization of synthetic image without noises.
K-means Clustering
In general, k-means clustering is used to cluster unlabeled data points that minimize their distance within the groups. It only needs setting of the number of cluster, k. For simple explanation, k number of imaginary data points are generate, what we call centroid, then each data points are grouped to the nearest centroid. Centroid is then moved to the average of the data points in that group, and the process is continued until convergence.
In vision tasks, k-means clustering can be used for intra-class clustering, clustering feature extractor output of each image in the same class. A good example of feature extractor would be the embedding function of a pretrained network to feature space. For example, some of the images in class plane may show the head of a plane while some of them may show the tail of a plane. Passing these two images through the feature extractor would give distant outputs while images with similar feature would give neighbouring outputs. Applying k-means clustering would group the images in that class with similar features. Selecting image from each cluster will well represent the distribution of whole dataset evenly. Simply put, this is how DREAM constitute the mini-batch for updating synthetic image stably and efficiently.
Training efficiency
DREAM studies varying factors in random sampling that result in optimization instability and degradation of training efficiency.
Firstly, gradients from samples in different regien varies. Samples in the center of distribution induces low gradient norm in the parameteric space since they have high prediction accuracy. Samples at the boundary, on the other hand, induces high gradient norm that would dominate the optimization direction. Gradient matching with supervision form unbalanced minibatch with these extreme samples will cause unstable optimization eventually leading to performance degradation. The paper empirically demonstrate the effect of training with such extreme samples.
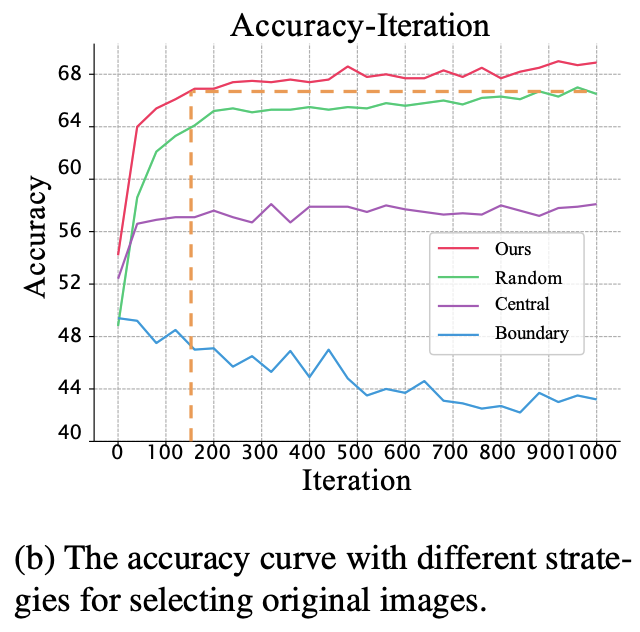
Secondly, random sampling for generating mini-batches cannot consistently cover the original dataset distribution of that class. With the following unevenly distributed sample for supervision, boundary samples may cause unstable and large gradient as a matching target. To investigate the phenomenom of uneven distribution in randomly sampled mini-batch, the paper shows the MMD, a distribution distance, of sampled mini-batch and actual real image distribution thorughout the iterations. They compare their method of constituting the mini-batch with random sampling. As the result shows, the ramdomly sampled mini-batch shows higher distribution distance from original dataset meaning that it does not represent the original distribution well. On the other hand, with the strategy of sample selection in DREAM mini-batch well represent the original distribution.
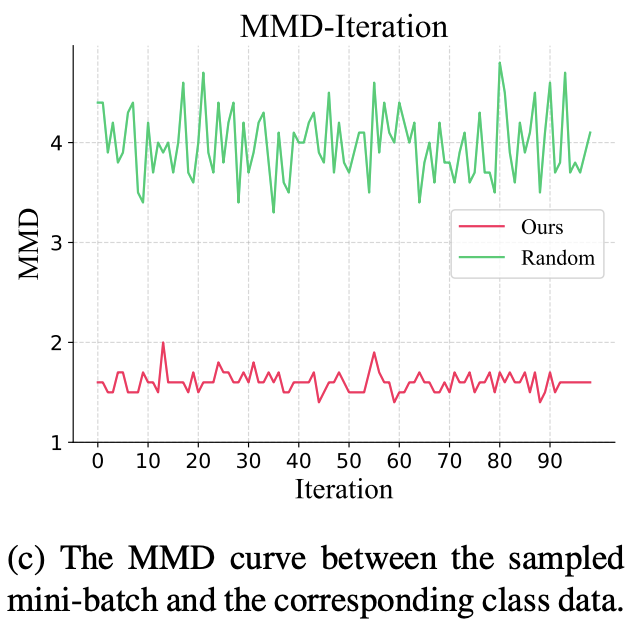
Constructing mini-batches for matching target
DREAM employs clustering process in order to construct mini-batch with representative samples as matching targets. Two principles that induces stable optimization is even distribution for avoiding biased supervision and accurate reflection of overall images in that class. Once again, bare in mind that gradient matching is conducted seperately for each class.
K-means algorithm is adopted to form intra-class clusters within each class. From each clusters representative samples are selected to form mini-batch for real image target. Such mini-batch would evenly cover whole class distribution with sufficient diversity, meeting the principles above. Defined in the experiment section of the paper, clustering process is conducted for every 10 inner loop iteration with cluster number equal to the mini-batch size for each class. Feature extractor of the matching model at that inner loop iteration is used for defining the feature vector of each sample. Each sample is clustered based on its feature vector. One sample nearest to the centroid of each cluster is selected to form a mini-batch.
Another different strategy is the initialization of synthetic images. Intra-class clustering is conducted at the start of the distillation process with number of cluster equal to the IPC. Then synthetic dataset is initialized with each cluster center (nearest to the converged centroid). Synthetic dataset would better reflect the data distribution giving a head start accelerating the distillation process.
The diagram below will give better understanding to the method implemented in DREAm and gradient matching method in general.
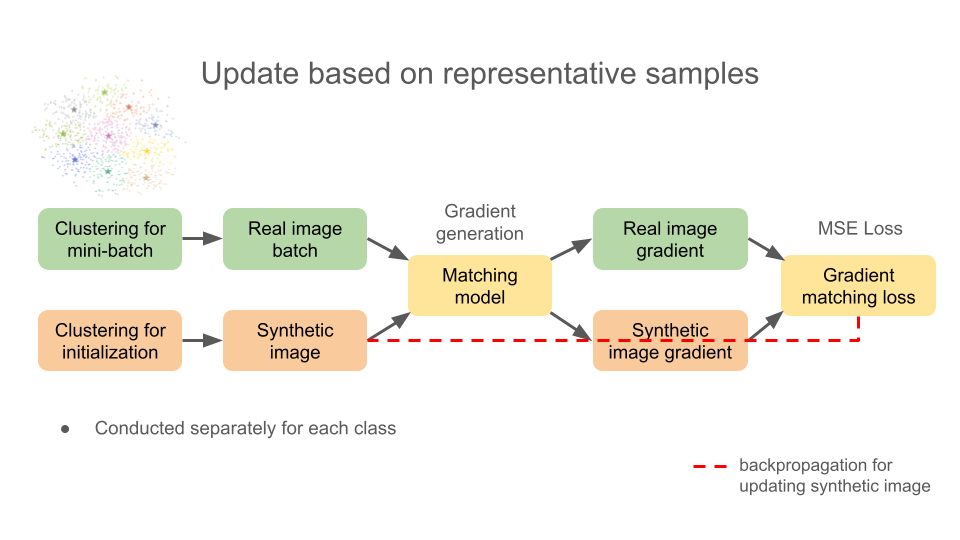
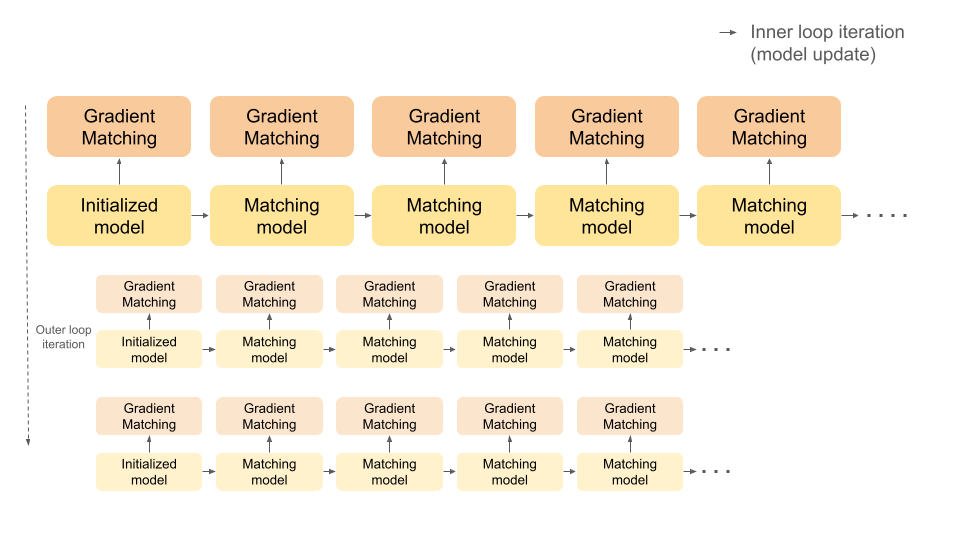
The overall process is the same with IDC method, while the performance of IDC is met with 8 times less iterations incorporating this strategy.
Experiment
Implementation detail
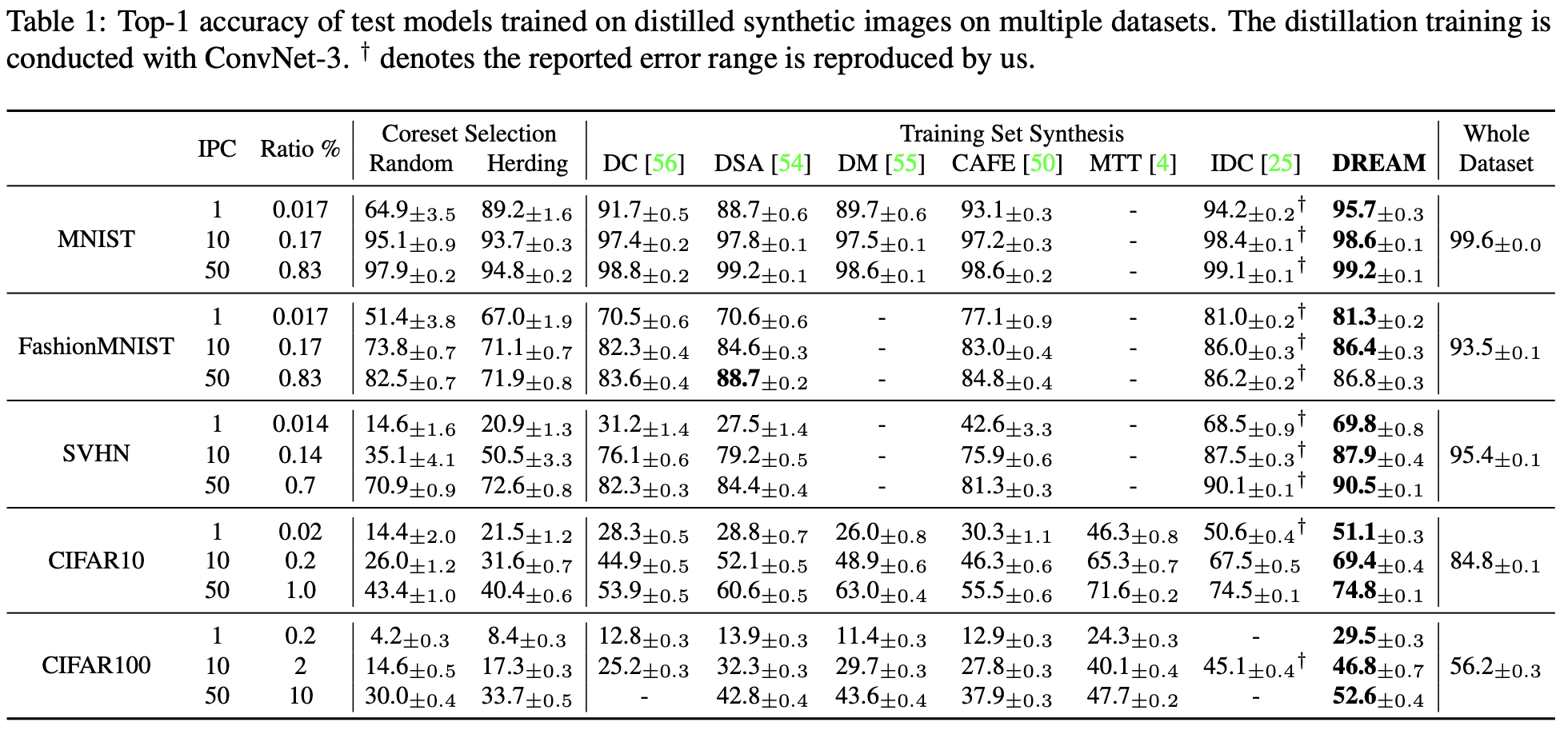
DREAM conducts distillation on the following benchmarks: CIFAR10, CIFAR100, SVHN, MNIST, FashionMNIST, TinyImageNet. Distillation is conducted on ConvNet-3 with 128 filters and instance normalization. Gradient matching is conducted with mini-batch size of 128. Gradient matching loss is computed with two different metric: MSE for CIFAR10/100, SVHN, TinyImageNet and mean absolute error for MNIST, FashionMNIST. Each distillation is conducted with 1,200 outer loops and 100 inner loop within. Testing the performance of synthetic image is referred to as ‘Evaluation’, which a model is trained on the synthetic dataset by batch gradient descent method for 1,000 epochs with learning rate of 0.01 and tested on the original validation dataset. Table below shows the performance of synthetic dataset generated with different benchmarks. DREAM shows high performance compared to the SOTA distillation methods.
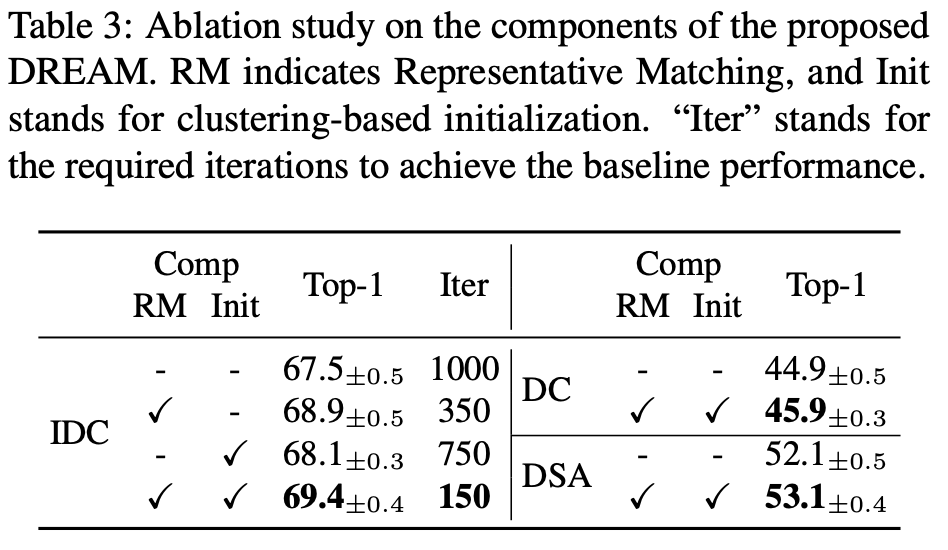
Ablation study
Two component of this method is construction of mini-batch, referred as representative matching, and initialization. Isolated and combined effect of these component is investigated by ablation as shown in the table below. We can observe that each of the component serves a performance boost in all three methods without loss of generality. With both the component DREAM achieves improved performance and cuts the required iteration by 8 times.
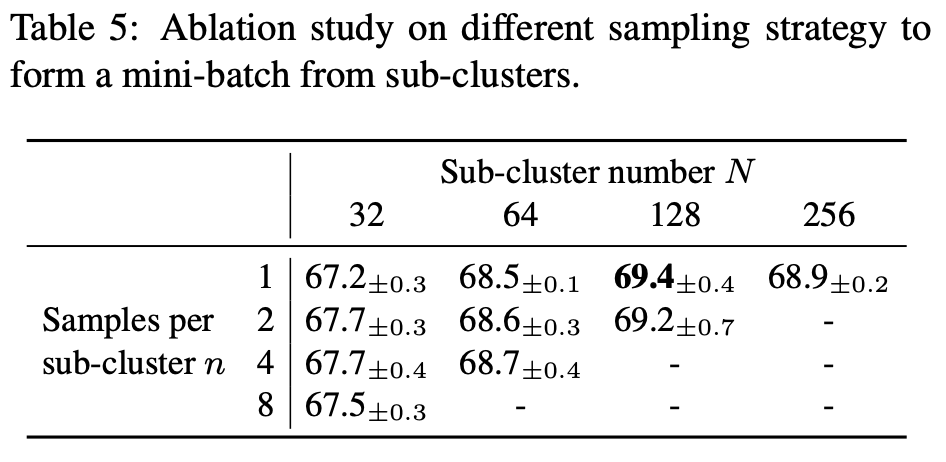
In representative matching, optimal mini-batch construction strategy is investigated through ablation study. Within N number of intra-class cluster top-n samples nearest to the centroid of each cluster is selected to construct the real image mini-batch. The table shows performance higher than IDC baseline of 67.5 almost consistently.
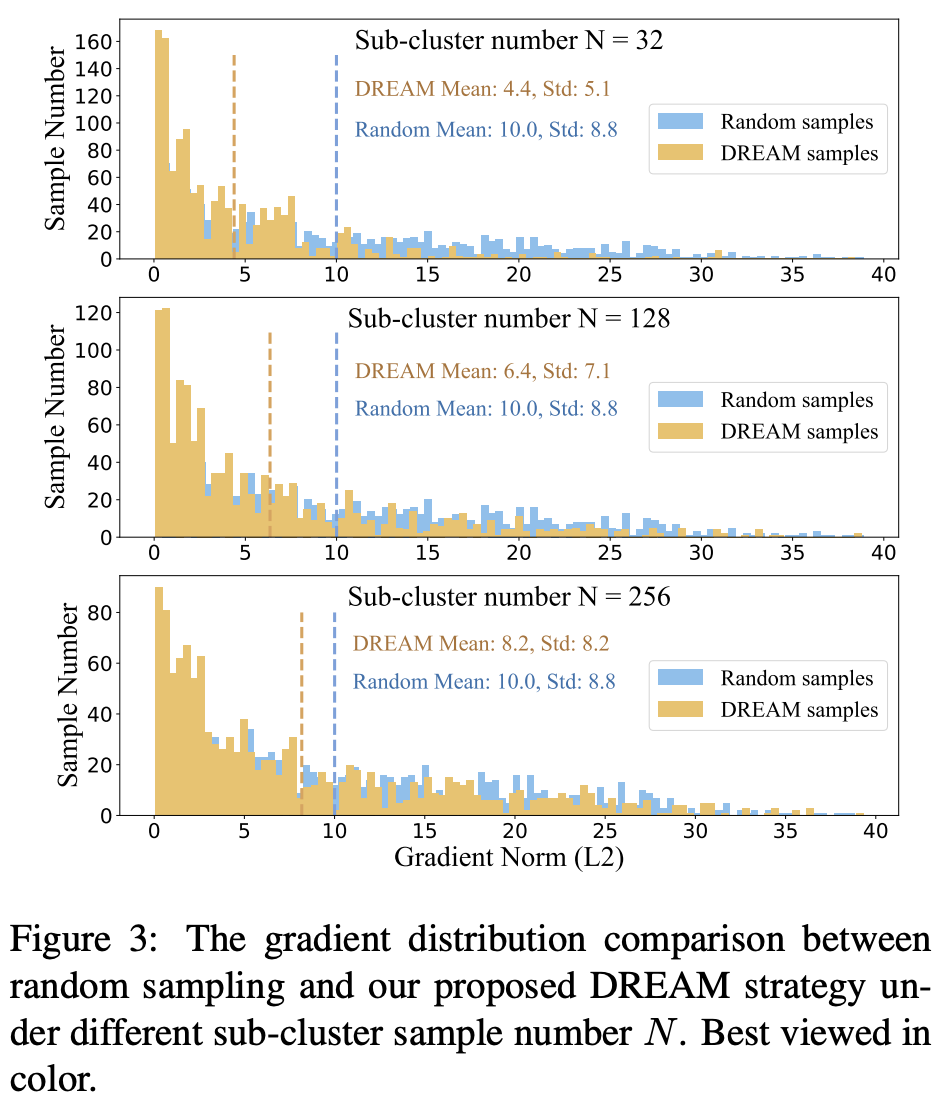
Further analysing the effect of the number of clusters N, the paper provides a reasonable evidence to why N = 128 has optimal performance based on the gradient norm of samples. Small cluster number induces samples with small gradient norms which provide less effective gradient supervision in later phase of training. High cluster number induces gradient norm distribution close to random samples, where we can expect similar performance to random sample methods.
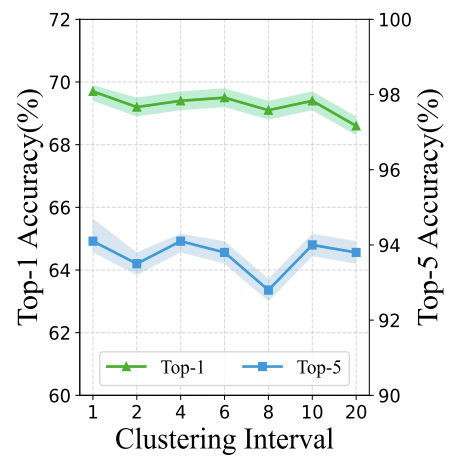
Another ablation study is determining the clustering interval. Regardless of the diminished iteration number, clustering process take up time as well. For CIFAR-10 distillation, image update take 0.2s for each inner loop training, whereas clustering process takes 1s. It seems important to balance the interval at which clustering is conducted in order to reduce the total training time. Paper suggests well compensated interval to maintaining the performance while minimizing training time through this ablation study. Hence the paper selects interval of 10 inner loop iteration for clustering resulting in an average of 0.3s per inner loop iteration still shortening the training time by up to 70%.
Analysis
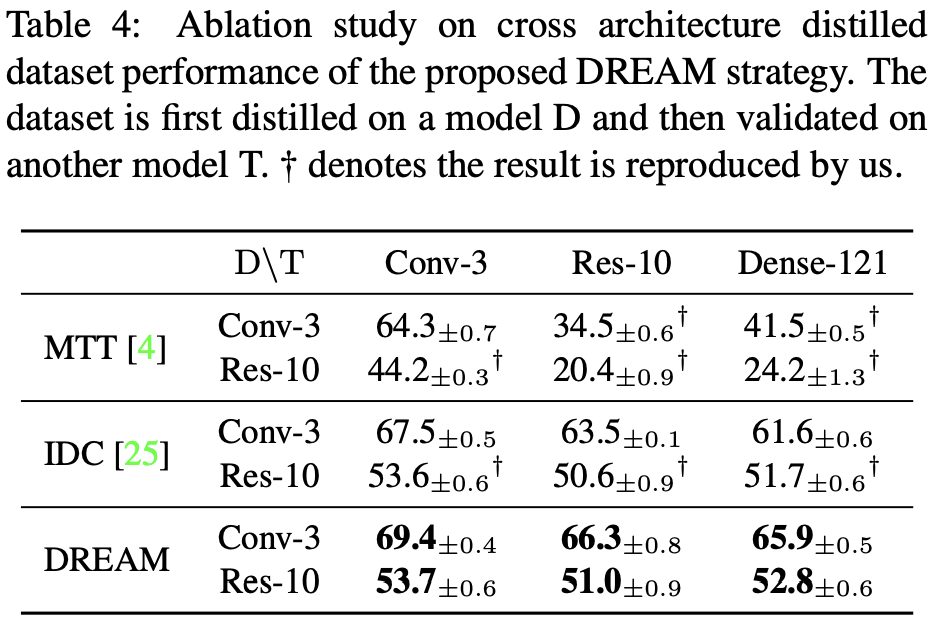
Cross-architecture generalization refers investigating the performance of synthetic dataset generated from single model, in this case ConvNet-3, being tested on different structured model, such as ResNet or DenseNet. Synthetic dataset may be overfitted to its matching model since there is no generalization to the varying model it can be utilized in the training process. DREAM method shows overall performance increase in different architecture verifing that it build a more reasonable dataset compared to previous methods.
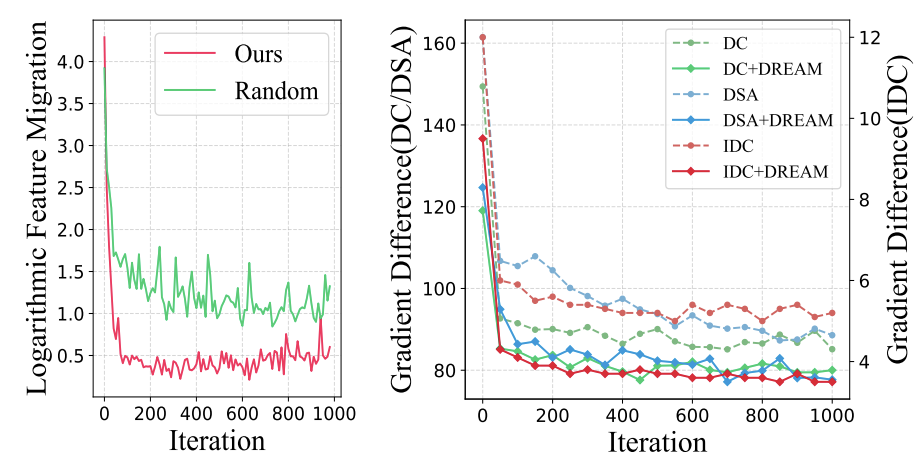
DREAM incorporates interesting analysis of the stability in synthetic images update, feature migration, comparing with previous random sampling method. This is conducted by recording the feature vector of synthetic image on random network every 10 iteration. Then, Euclidean distance with its adjacent feature vector is recorded to monitor the change in synthetic image feature. From the graph below synthetic image from DREAM method converges to optimal poisition wihtin 100 iterations, whereas from random sample supervision there is still a high fluctuation due to noisy matching targets. Moreover, training loss curve of DC, DSA[4], IDC method is compared with its DREAM plugged-in version. This also shows a faster, lower, and more stable curve with the method added.
The paper observes the qualitative result of DC+DREAM compared to DC. A more clear characteristic of the class can be observed, as well as introducing more variety to the synthetic image for DREAM method.

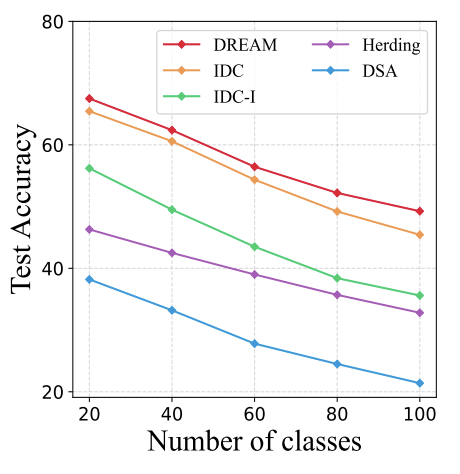
Another application of dataset distillation can be continual learning. Continual learning is the process of adding new tasks while not forgetting the previous tasks. In this case, 5-step class-incremental learning is conducted with CIFAR-100 dataset where task refers to each class. Basically model is trained on synthetic dataset of 20 classes at first then the next 20 classes consequtively, then the cummulated classes are tested for accuracy. From the graph below we can observe that DREAM consistently maintains higher performance. This means that the synthetic dataset represent better discriminative information that can be less forgotten.
Closing Remark
DREAM successfully addresses training efficiency problem while even increasing performance by matching with the representative samples. DREAM is a successful plug and play method that can be incorporated into DC, DSA, IDC, and even DM methods. DREAM+[6] is another paper that incorporates both gradient matching and distribution matching to boost overall performance. However, further work is required to mitigate the computational burden in distilling much larger dataset such as ImageNet.
Reference
[1]Liu, Yanqing, et al. “Dream: Efficient dataset distillation by representative matching.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
[2]Kim, Jang-Hyun, et al. “Dataset condensation via efficient synthetic-data parameterization.” International Conference on Machine Learning. PMLR, 2022.
[3]Zhao, Bo, Konda Reddy Mopuri, and Hakan Bilen. “Dataset condensation with gradient matching.” arXiv preprint arXiv:2006.05929 (2020).
[4]Zhao, Bo, and Hakan Bilen. “Dataset condensation with differentiable siamese augmentation.” International Conference on Machine Learning. PMLR, 2021.
[5]Zhao, Bo, and Hakan Bilen. “Dataset condensation with distribution matching.” Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.
[6]Liu, Yanqing, et al. “Dream+: Efficient dataset distillation by bidirectional representative matching.” arXiv preprint arXiv:2310.15052 (2023).
[7]Wang, Tongzhou, et al. “Dataset distillation.” arXiv preprint arXiv:1811.10959 (2018).
[8]Cazenavette, George, et al. “Dataset distillation by matching training trajectories.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[9]Yin, Zeyuan, Eric Xing, and Zhiqiang Shen. “Squeeze, recover and relabel: Dataset condensation at imagenet scale from a new perspective.” Advances in Neural Information Processing Systems 36 (2024).
