Reinforcement Learning in grid world
We implemented Deep Q-learning for agent reaching goal passing obstacles in grid world. We trained MLP to output Q values of four possible actions from input of current coordinate(position) of the agent. This network is trained from the stored history of state-action-reward-next state quadriplet.
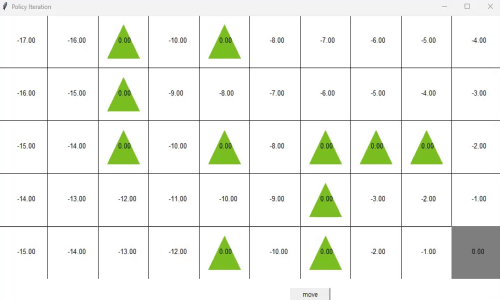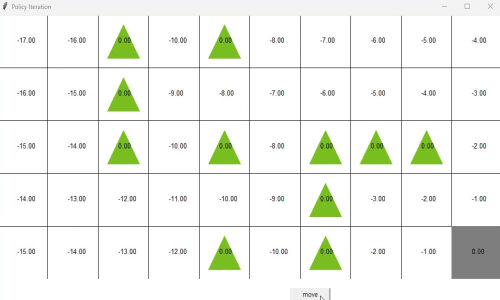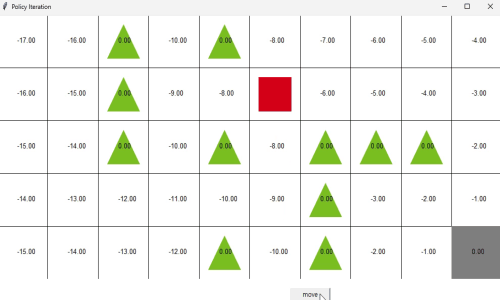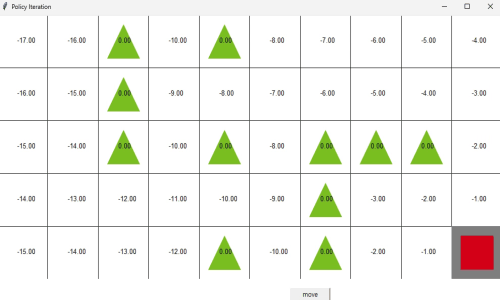
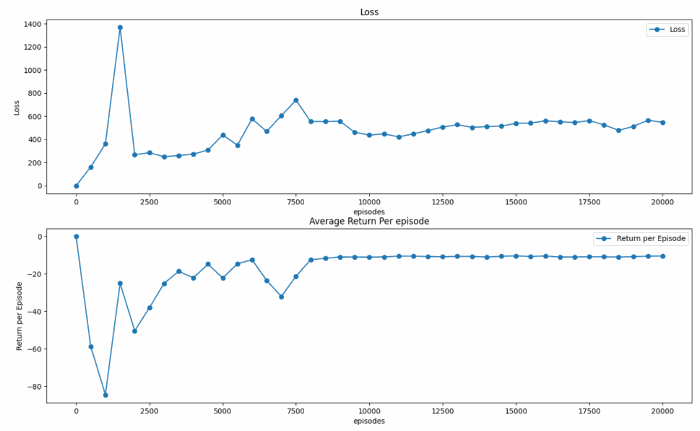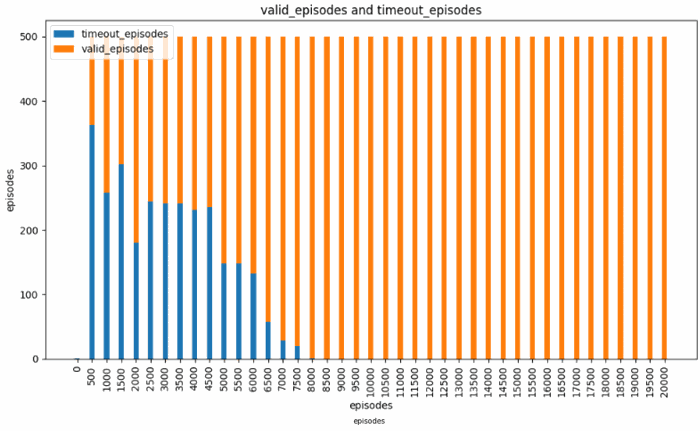
Observation from this experiment includes the average return of each episode as the training progresses and the ratio of goal reached episode over timeout episodes.